What is Unstructured Data & How to Analyze It for Business Insights

The information age has brought with it a deluge of data, both structured and unstructured. The collection of data is growing every single day. In this, it is estimated that a staggering 80 to 90% is unstructured. The growth rate of unstructured data is about 65%. Let’s understand what unstructured data is.
What is Unstructured Data?
Unstructured data is qualitative data that cannot be arranged using existing data analysis models. It is, therefore, difficult to parse such data using traditional analytics methods.
Since there are no pre-existing relational models for such data, it is stored and managed either through non-relational databases (NoSQL) or through data lakes where it can be preserved in the raw form. Examples of unstructured data include emails, texts, social media, mobile data, images, audio or video files, etc.
Structured vs Unstructured Data
Get a detailed explanation on Structured vs Unstructured Data and analysis from our latest article.
Structured data is quantitative data such as that found in financial systems and business applications. Such data is presented in a traditional format and thus is easy to store, process, and analyze.
Unstructured data, on the other hand, is presented in non-traditional formats. To store and parse such data is therefore not simple.
RDBMS or a relational database, where structured data is stored, provides direct access to exclusive data points that are presented in columns or tables.
For example, a spreadsheet with customer information can provide access to customer phone numbers, emails, addresses, etc., as these are presented as separate columns in the same spreadsheet. Travel booking systems, accounting remittances, and inventory registers are other examples of structured data.
The way structured data is presented is considered stable and easily searchable through SQL or structured query language. Both humans and algorithms can easily search the relational databases for information from structured data.
On the other hand, it is easy neither to store nor to search and analyze unstructured data. Since such data is qualitative, it is not usually possible to arrange it in columns or tables.
Thus, unstructured data analysis is difficult as the formats in which such data is stored are typically digital representations that do not have character orientation.
While the storage of some types of unstructured data may require less space, most unstructured data is available in huge files that require more storage space. Since structured data is available in rigid formats, it usually requires more storage space to accommodate the specific structures.
What is Semi-structured Data?
Semi-structured data is mostly unstructured data with some markings and internal tags. For example, the metadata of emails makes them semi-structured.
Internal tags help place the data elements in different pairs and hierarchies, thus making the data semi-structured. It is possible to search specific emails and also classify them based on these internal tags.
Apart from emails, data from sensors, social media, and markup languages like XML and NoSQL databases all use markings and internal tags and gradually become searchable. Such data is categorized as semi-structured.
Examples of Unstructured Data
Humans and machines can both generate unstructured data.
Human-generated unstructured data includes:
- Emails
- Text files such as word documents, PowerPoint presentations, excel sheets, etc.
- Data generated from social media websites and applications such as Facebook, Instagram, Twitter, LinkedIn, etc.
- Data generated from mobile phones such as SMS, call recordings, chats, instant messages, etc.
- Other media such as audio, video, images, etc.
Machine or software generated data includes:
- Images from satellites such as those for weather conditions, landform updates, military movements, etc.
- Digital surveillance using cameras and drones for images and video footage
- Scientific data from seismic imagery, space exploration, etc.
The problem with all such data is that it cannot be organized into an analytics-friendly format. Only very advanced AI technology can enable the analysis of such data.
Large amounts of unstructured data thus go unsearched and unexploited. Users find it a waste of time to sift through such enormous data. However, new technology, such as text analysis techniques, now makes it possible to cull information from such databases and put it to use.
While social media is a mine of information, most data exist in a nebulous, unsearchable format. Hashtags, however, make part of this data searchable. Hence, when brands or products are mentioned using hashtags, opinions about such brands and products can be mined and analyzed.
Machine Learning tools can be utilized to learn in-depth about the current trends and do a social media sentiment analysis about the concerned brand or product.
Customer feedback and surveys contain a world of information, but most of it is again unstructured. Tracking customer needs and feedback on a regular basis by using technique such as customer sentiment analysis can reveal a lot about customer concerns and save response time. It can also improve customer satisfaction.
Like everything else on the internet, web pages are also evolving. All types of content — text, audio, video, and images — appear on web pages. Using Machine Learning software can be useful for tracking and referring web pages over time. Similarly, responses to open-ended surveys can bring much insight. Business intelligence tools help gather and analyze data from open-ended surveys.
How to Analyze Unstructured Data?
While there have always been copious amounts of unstructured data offering a chance to gain in-depth insight, the actual learning from such data has been limited. This is because the analysis had to be done manually.
The document management systems handled indexing, version histories, and other metadata, but there was no other way to analyze this data precisely.
Now, though, there are many data analytics tools available. These tools have been specifically designed to break down unstructured data into components that can be stored in a searchable format.
Machine Learning and Natural Language Processing help in creating Deep Learning Software which becomes sophisticated unstructured data analysis tools. Through Deep Learning, these software programs become trained to cater to the needs of specific industries.
Here’s a look at how to manage unstructured data for analysis and further use:
- Define the objective: Just like any computer program, it is important to establish the objectives for the unstructured data analysis. This is important because unstructured data can provide a sea of information, and the insights can be lost in translation. Having a clear objective will guide the program in a specific direction and use those unstructured data components that will help attain the goal.
- Gather the right data: In this information age, data can be collected from a wide variety of sources. If the objective is in place, it is easy to decide the sources from where to gather data and the type of data — real-time or historical — to be gathered. However, at different junctures, data from a particular source such as online surveys, social media, or email feedback might be needed to gather relevant insights.
- Pre-process data: Computer programs are sophisticated and require data in a certain format. Thus, you will need to clean the data to reduce noise and eliminate extra elements.
- Use technology: The information age wouldn’t be a reality if not for the technology that makes information accessible. For conducting an in-depth analysis of unstructured data and glean relevant insights, it is important to use Deep Learning software in conjunction with NoSQL databases to manage data flow and tools like Google Data Studio and Tableau that can help summarize visual data.
After deploying such technology, insights garnered can be presented through beautiful charts and graphs. Your team can understand the insights in a much easier way and thus, decide the actionable steps.
An Example Of How Machine Learning Does Unstructured Document Analytics
Let’s take an example of a legal document analyzer we built to help lawyers automate the process of document reviews.
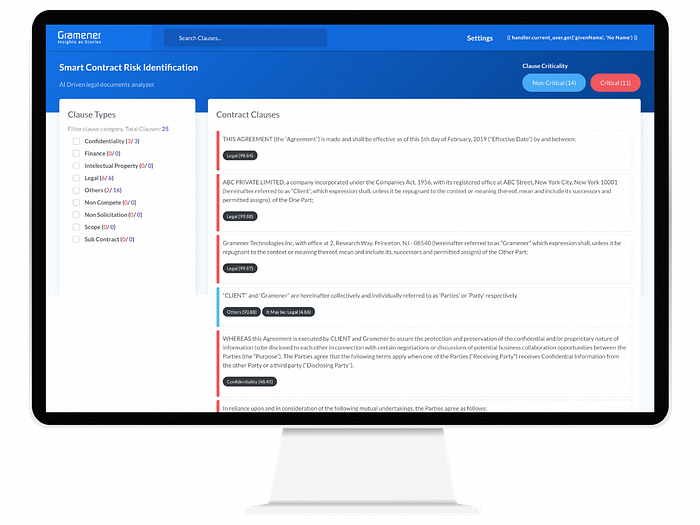
Smart Contract Risk Identifier (SCRI) is a legal document analyzer driven by AI that supports attorneys in conducting exact legal document evaluations. Legal documents may be fairly complex, with hundreds of categories and key clauses.
Manually evaluating a Non–Disclosure Agreement (NDA), for example, may take many hours.
Our solution categorizes a whole document based on clauses. It helps lawyers to quickly assess the gravity of a provision and act on the most essential ones.
This tool saves many precious hours, allowing professionals like attorneys to concentrate on more productive tasks.
Here’s a look at some important unstructured data analytics tools.
Unstructured Data Analytics Techniques
Named Entity Recognition
Named Entity Recognition (NER) assists you in quickly identifying essential aspects in a text, such as names of people, locations, brands, monetary values, and more.
Extracting the major entities in a text aids in the sorting of unstructured data and the detection of significant information, which is critical when dealing with big datasets.
NER is utilized in many disciplines of Natural Language Processing (NLP) and may assist in addressing numerous real-world queries, such as:
- Which firms were mentioned in the news article?
- Were specific goods referenced in customer complaints or reviews?
- Is there a person’s name in the tweet? Is this person’s location mentioned in the tweet?
At Gramener, we use the NER technique for a leading pharmaceutical organization to anonymize patients’ personal information during clinical trials.
Gramener is assisting a worldwide healthcare organization with an automated method for anonymizing public healthcare information.
Clinical study documentation can run into hundreds of pages. These summaries are then submitted to regulatory bodies such as the FDA. Clinical research institutions must guarantee that the materials do not contain any personal information about the participants. As a result, they must undertake the huge effort of manually cleaning out the data.
Text Analysis
Text analysis (TA) is a machine learning approach that extracts important insights from unstructured text data automatically. Text analysis tools are used by businesses to swiftly ingest web data and documents and translate them into actionable insights.
Text analysis may be used to extract particular information from hundreds of emails, such as keywords, names, or corporate information, or to categorize survey replies based on attitude and subject.
Our client, a prominent pharmaceutical producer, performs clinical studies all over the world. The process of conducting clinical trials is time-consuming, and every detail counts. A study might be delayed for months or even years if a single step is handled incorrectly.
Firms must locate patients who meet the study’s criteria as part of a clinical trial. This necessitates sifting through 7 million documents containing information on the trials’ numerous aspects. Our solution automates this mammoth job by creating a metadata store of 7 million documents.
It uses text analysis to identify all of the elements in the document, then builds aggregated metadata and processes it to make it searchable.
This significantly reduces the time and effort involved.
Aspect Based Sentiment Analysis

Aspect-based sentiment analysis (ABSA) is a text analysis approach that divides data into aspects and determines the sentiment associated with each one.
Customer feedback may be analyzed using aspect-based sentiment analysis by correlating distinct attitudes with different characteristics of a product or service.
Aspects are the qualities or components of a product or service, such as “the user experience of a new product,” “the response time for an inquiry or complaint,” or “the ease of integration of new software.”
Here’s a rundown of what aspect-based sentiment analysis may uncover:
- Sentiments: Positive or negative feelings concerning a specific topic.
- Aspects: The category, characteristic, or issue being discussed
Aspect Based Sentiment Analysis (ABSA) is used by our AI-powered Customer Feedback Analyzer to help businesses understand the sentiment associated with a certain attribute or aspect.
ABSA is a text or voice analytics technique that categorizes data based on specific variables to determine the underlying sentiment or mood.
For example, the analyzer can exactly assess client sentiments on the quality of a product. This is a step up from standard text or speech analysis technology since it dives into customer preferences and experiences.
Unstructured Data Analytics Tools
As discussed earlier, unstructured data is almost 8 to 9 times more than available structured data. The consequent benefits of unstructured data can also be those many times, but there has to be a way to look into such huge amounts of data. Thanks to new-age technology, this is now becoming possible. But it’s only the tip of the iceberg that companies are beginning to scratch.
Even so, AI-based technology is helping create industry-specific programs to help industries unearth insights from the dumps of data they create on an ongoing basis. The past few years have been particularly good in this regard. The future looks even more promising, with new developments in AI taking place at a fast pace. Let’s take a look at some such tools that are helping companies mine insights.
Gramex
Gramex is Gramener’s flagship data science platform that can build data & AI apps 50% faster than conventional software development methods.
Gramex is capable of building Machine Learning applications that can analyze customer data or reviews that are scattered online in an unstructured format.
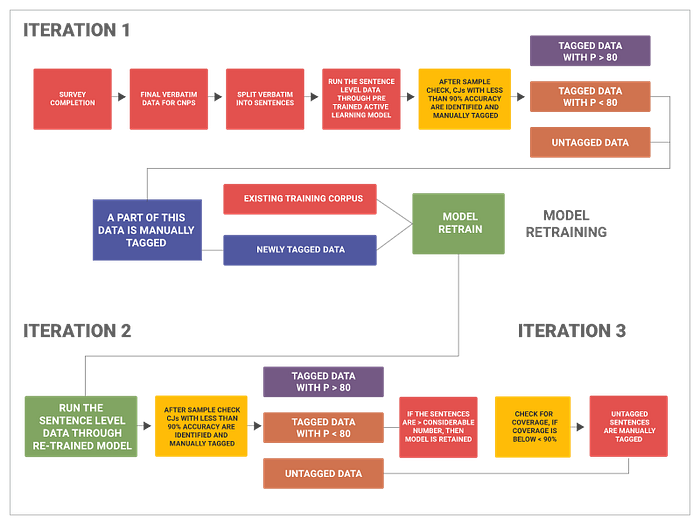
The image below is the process of an ML application, built by Gramex, that calculates the Net Promoter Score (NPS) value for a wide range of unstructured customer reviews.
Some of Gramex’s pre-trained models that you can use to collect insights from your unstructured data are Sentiment analyzer, Name extractor, Keyword extractor, Intent, and Email classifier, and Survey Feedback analyzer.
MonkeyLearn
This is a powerful, modifiable, and scalable SaaS solution that does text analysis. With a full range of Machine Learning based SaaS text analysis on offer, this tool has easy-to-use APIs in all important programming languages. Hence, integration with current processes is a breeze.
It uses techniques like sentiment analysis to automatically scan for positive, negative, or neutral sentiment around a topic.
Training the text analysis models for specific needs is a plum job. Even integrating current applications like Google Sheets, Excel, Zendesk, Zappier, etc., is simple.
Amazon AWS
This is another versatile tool that can be used across a wide variety of industries. Amazon S3 enables you to move, store, manage, and protect any organized and unstructured data at an infinite scale, dismantling data silos.
One can search the Amazon Marketplace for the prolific digital catalog of vendors of all sorts of industry-specific programs. These programs can be used on the Amazon cloud.
Microsoft Azure
This is a tool for global companies that want coverage across different regions of the world. If you have a huge workload and a steady flow of unstructured data that needs to be analyzed in real-time with no downtime, then Microsoft Azure’s Stream Analytics is the tool to go for.
It is custom-built and can integrate with your current system with ease. You can customize models using Microsoft Azure Resource Manager. Any existing models could be transported to Azure Analysis Services for the scalability and flexibility that the cloud offers.
IBM Cloud
Another tool for the large companies that wish to shift their storage and analysis to the cloud. With IBM Cloud Analytics, you can easily shift your existing models to the cloud and bring your data analytics to one place. With IBM Cloud, you can have a complete architecture at your disposal with no need for unnecessary investments in single-point solutions.
Pros of Unstructured Data
Everything comes with pros and cons. Let’s take a look at some of those for unstructured data:
- Native Format: Unstructured data is available in its native format. Since it is undefined, it has great adaptability, thus enabling a large number of file formats. This increases the overall data pool and makes it easy for data scientists to search and analyze specific data.
- Fast collection: No need to structure means that the data can be collected as is. This enhances the speed of gathering data.
- Storage in Data Lakes: Data Lakes offer a pay-per-use model, whereby companies only pay for the actual amount of storage space they use.
Cons of Unstructured Data
- Needs experts: Undefined data format means there is a need for expert data scientists who can parse unstructured data for valuable insights. While this may not be a problem for data experts at all, the untrained business users can be left confused and not know how to gain insights from the unstructured data.
- Needs special tools: Industry-specific and need-specific tools are needed for text mining and text analysis of unstructured data. Thus, managers have little to no choice in terms of product offerings.
Benefits of Unstructured Data Analysis
The pool of unstructured data is vast, and if one can conduct unstructured data analysis, the insights accumulated can make the business grow exponentially. Unstructured data analysis tools are powered with Machine Learning and Natural Language Processing, enabling them to conduct automatic research on consistent data flow sources such as emails and customer service requests.
The biggest advantage is that machines don’t tire, unlike humans. Humans can get easily bogged down by the vast amounts of data. So, their analysis results may be skewed. Specialized unstructured data analysis tools, on the other hand, produce accurate, real-time time results fast and consistently.
Use Cases of Unstructured Data Analysis
While simple content searches are possible for unstructured textual data, in-depth search and analysis require AI/ML-based software programs. Using these programs can reveal previously unknown insights. Here are some of the things unstructured data analysis helps in:
- Data mining: Businesses need to know what their customers are thinking and what they need or want. Unstructured data analysis can help dig such data to help businesses align their offerings with these needs.
- Predictive analytics: Businesses can keep in sync with the pulse of the market. Unstructured data analysis can provide market alerts and help businesses prepare for any crucial shifts in the market.
- Chatbots: Perhaps one of the most valuable AI tools is the chatbot. These chatbots are trained to answer a fair share of customer queries with deep learning, only answering more complex questions to the human resources.
- Regulatory compliance: unstructured data analysis can also help maintain regulatory compliance by tracking and analyzing all official communication.

